SELECT DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT FROM (SELECT SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT FROM ONLINE_SALE UNION ALL SELECT SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT FROM OFFLINE_SALE ) AS A WHERE SALES_DATE LIKE '2022-03%' ORDER BY SALES_DATE, PRODUCT_ID, USER_ID
※UNION : 중복제거 + 테이블 세로로 결합(위+ 아래) ※UNION ALL : 중복제거X + 테이블 세로로 결합(위+ 아래)
문제에 있는거 그대로 따라갔다. ONLINE_SALE에서 필요한거 그대로 가져오고, OFFLINE_SALE테이블에서 필요한거 그대로 가져오고 결합 (UNION은 위아래로 단순하게 붙이는 것이기 때문에 컬럼만 맞으면 나중에 지장은 없다)
OFFLINE_SALE 에서 USER_ID는 NULL로 하라고했기에 NULL을 중간에 넣어줬다
단순하게 붙이면 이런 결과가 나오고 이 테이블을 가지고 다시 조건출력하면 끝
최종쿼리
A2. WITH사용
중간에 결합된 테이블을 바로가져왔지만 WITH 함수를 이용하여 테이블 지정후 작성해도 풀 수 있다
로지스틱회귀 (Survived를 종속 변수로 하고, Gender, SibSp, Parch, Fare를 독립 변수) from statsmodels.formula.api import logit result = logit('Survived ~ Gender+SibSp+Parch+Fare', data =df ).fit().summary() print(result)
선형 회귀분석(Survived를 종속 변수로 하고, Gender, SibSp, Parch, Fare를 독립 변수)
import statsmodels.api as sm import statsmodels.formula.api as smf
SELECT A.ITEM_ID, A.ITEM_NAME, A.RARITY FROM ITEM_INFO AS A LEFT JOIN ITEM_TREE AS B ON A.ITEM_ID = B.PARENT_ITEM_ID WHERE B.ITEM_ID IS NULL ORDER BY A.ITEM_ID DESC
N차세대 부모-자식관련 문제를 풀 땐 조인을 이용하여 생각해야한다. 그리고 이 문제는문제에 두 테이블은 분리가 되어있는 것 처럼 보이지만PARENT_ITEM_ID만 따로 분리했다고도 볼 수 있다. 그래서 어떻게 결합하냐에 따라 문제를 보다 쉽게 해석할 수 있게된다.
처음에ITEM_ID는 자식,PARENT_ITEM_ID는 부모를 의미하고있다.
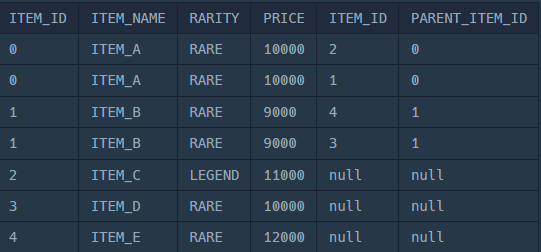
그렇다면 테이블 두개를ON A.ID = B.PARENT_ITEM_ID 로 결합하게 된다면 부모-자식간 관계가 보인다
두 테이블을 ON A.ID = B.PARENT_ITEM_ID 로 결합했을 경우
좌측A. ITEM_ID는B.PARENT_ID부모포지션으로 같아지고
B.PARENT_ID의 자식B. ITEM_ID는 A.ITEM_ID의 자식으로 볼 수 있다.
즉 아래와 같은 테이블로 볼 수 있다
이 이후엔 업그레이드가 불가능한 조건 ( = 자식이 없는 부모,WHERE B.ITEM_ID IS NULL)을 구하면 된다